
Los modelos de lenguaje extenso (LLM, también llamados modelos lingüísticos grandes) hacen que los bots conversacionales sean uno de los mejores inventos, ya que permiten la comunicación entre los usuarios y los asistentes virtuales al resolver dudas cotidianas.
Los bots son el resultado de un largo entrenamiento, como si hubieran leído miles de libros y páginas web, y hubieran escuchado conversaciones a lo largo de su vida, y hubieran aprendido a hablar como nosotros. Este entrenamiento se convierte en una especie de «cerebro» que puede entender lo que dices, responderte y aprender cosas nuevas con cada conversación. Por tanto, un buen modelo es aquel que se ha entrenado millones de veces y seguirá haciéndolo para responder a todas tus dudas.
¿Qué ofrecen?
Los chatbots con LLM son tan prácticos que basta con escribir en una caja de texto y conversar. Estas ofrecen varias opciones:
- Responder preguntas: desde un simple «hola, ¿cómo estás?» hasta «¿podrías decirme cuál es el tamaño de la Tierra?».
- Generar ideas: Contar un chiste, elaborar un poema. Nunca tendrán sentimientos, pero algo es algo.
- Traducir frases. Depende del LLM en cuestión. Si tienen más capacidad, podrán entender varios idiomas y enseñarte.
- Ser tu profesor: Aprendes algo nuevo.
Los bots conversacionales con LLM son la nueva revolución en el mundo digital. Así que prepárate para esta aventura, pero siempre con responsabilidad.
¿Cómo elegir un buen modelo de lenguaje extenso?
Para que un bot de conversación funcione de acuerdo a tus necesidades, deberás utilizar un buen modelo. Algunos son específicos y otros son más generales. Debes revisar qué ofrece cada modelo para incorporarlo, descargarlo (si quieres trabajar sin conexión a Internet) y usarlo.
- El nombre del modelo.
- La cantidad de parámetros (medidos en millardos de parámetros).
- Según la cantidad de parámetros, se exige un alto consumo de memoria RAM y de espacio en disco. Puedes revisar la sección Requisitos para más detalles.
- Hay que tener en cuenta que existen parámetros activos y parámetros incrustados que se pueden utilizar cuando sea necesario. Por ejemplo, el modelo Gemma E4B consta de 4 mil millones de parámetros activos y más de 4 mil millones incrustados.
- La calidad del modelo. En muchos casos, no suelen ser relevantes para los usuarios, pero son importantes para calcular la calidad de los datos en el momento en que la computadora los lea.
- En cualquier caso, el modelo de cuantificación sin comprensión es de FP16 y luego sigue de Q8 a Q1. Se recomienda un cuantificado de Q4.
- Los modelos van mejorando la calidad a medida que se van introduciendo mejoras en la cuantización, como es el caso de caché K/V (key-value). Cuanto mejor es la caché, menos recursos se consumen en conversaciones más largas.
- Gemma4 permite usar la cuantificación QAT, optimizado para GPU.
- Soporte multimodal. Si bien la mayoría de los chats solo aceptan texto, algunos de ellos también soportan imágenes, vídeo o documentos. Por ejemplo, las variantes Vision de Llama 3.2 (11 B) y Gemma 4 (E4B) permiten imágenes, lo cual es de agradecer.
- Función de razonamiento. Muchos usuarios lo considerarían intrascendental, pero es fundamental que el bot «piense antes de hablar» para ofrecer respuestas coherentes. Gemma 4 y Deepseek R1 cuentan con esta característica.
- Licencia. Sea uso comercial o uso personal.
Hay varios ejemplos de marcas. Hay que diferenciar Gemma y Llama de Gemini y ChatGPT, ya que estas últimas suelen requerir un servicio de terceros y tienen un coste de uso.
¿Qué modelo puedo empezar a usar?
Para cualquier usuario común y corriente, recomendamos usar Gemma 4. Este modelo es de código abierto, no tiene restricciones legales y dispone con multimodalidad (texto e imagen) y razonamiento. Cuenta con dos versiones para dispositivos de pocos recursos, E2B (dos millardos de parámetros) y E4B (cuatro millardos, siendo nueve millardo el máximo alcanzable). Estos modelos admiten opcionalmente QAT, siglas de Quantization-Aware Training, diseñada para aprovechar el máximo rendimiento en tarjetas gráficas compatibles y teléfonos inteligentes. Los modelos con QAT llevan un sufijo a lado del nombre de los modelos como gemma4:e2b-it-qat (además de gemma4:e2b-it-qat-mobile, que solo soporta LiteRT para Android).
Para Gemma 4 se ha sugerido para empezar a operar Gemma Turbo, de Daniel Elliott, que es un derivado con nueva cuantificación (int4 con ayuda de llama.cpp) para realizar tareas con rapidez y con menos recursos (entre 8 y 10 GB de RAM en la versión de alta calidad). Destaca por no exigir una tarjeta de video, haciendo que las conversaciones en el equipo sean fluidas. Se necesita entre 4 y 7 GB de espacio de almacenamiento libre. No genera imágenes aún. Gemma Turbo cuenta con dos ediciones: la que ofrece alta calidad y la ofrece altísima eficiencia (sin leer imágenes).
Hay que hacer algunas aclaraciones. Gemma 4 es recomendable por ser la primera versión de código abierto de Google. Otros modelos de Gemma disponen de términos de servicio que no recomendamos usarlos. Gemma 4 también cuenta con 12B (que facilita la traducción multimodal) e incluso con 31B, que permiten realizar tareas más avanzadas pero se recomienda equipos de 48 GB de RAM o más.
Si usas Ollama, estos son los comandos que puedes revisar. Estos son para la edición E4B (frontera 4B+4B):
ollama run gemma4:e4bollama run gemma4:e4b-it-qatollama run ssfdre38/gemma4-turbo:e4bollama run ssfdre38/gemma4-nano:e4b
Estos son para la edición E2B (frontera 2B+2B):
ollama run gemma4:e2bollama run gemma4:e2b-it-qatollama run ssfdre38/gemma4-turbo:e2bollama run ssfdre38/gemma4-nano:e2b
Estos son para la edición 12B (no usa embebidos y es más ligera que E4B en PC gama media-alta):
ollama run gemma4:12bollama run gemma4:12b-it-qatollama run ssfdre38/gemma4-turbo:12bollama run ssfdre38/gemma4-nano:12b
¿Hay más modelos?
Si quieres usar otros modelos, echa un vistazo a estos experimentos basados en Qwen 3.5:
- Qwen3.5 (0.8B, 2B, 4B y 9B) y posteriores, permite responder a ejercicios matemáticos universitarios escritos. Inicialmente soportaba inglés y chino. Cuenta con una variable Math y otra ASR para razonamiento matemático y multimodal. El modelo es mayormente de código abierto. Soporta AWQ, análogo a QAT pero requiere que la plataforma lo soporte.
- Para Ollama (para 9B):
ollama run qwen3.5:9b
- Para Ollama (para 9B):
- DeepSeek V4 Flash, una versión de código abierto conocida por consumir pocos recursos y ser capaz de razonar y de realizar ejercicios de matemáticas y ciencias de educación secundaria de manera aceptable. Existen varios modelos no oficiales destilados para Llama y QWen. El modelo sugerido es QWen 3.5 9B Unsloth Deepseek V4, desarrollado por Jackrong y Kyle Hessling, con soporte agéntico y potenciado por Unsloth (ver documentación).
- Para Ollama:
ollama run pdurugyan/qwen3.5-9b-deepseek-v4-flash-Q4_K_M-v_2
- Para Ollama:
- Qwen 3.5 con Opus Reasoning. Desarrollado por Jackrong. Usa la tecnología de Claude como alternativa a DeepSeek, aunque es propietario. Ver doumentación.
- Qwopus3.5. Desarrollado por Jackrong. Inspirado en OpenAI o1.
Además de Qwen 3.5, existen otras marcas que puedes considerar:
- Llama 3.2 de Meta (3B), atiende ocho idiomas. Disponible con restricciones en uso comercial. No se recomienda para todos los usuarios.
- SmolLM (1.7 B, solo inglés) para tareas generales. Intenta buscar en Internet «lightweight LLMs» para encontrar modelos similares. No está diseñado para tareas avanzadas.
- Deepcogito, un proyecto experimental para desarrollar un sistema de razonamiento híbrido. En otras palabras, se ajusta a tus necesidades y evita que el sistema se ralentice demasiado, lo que te permite disfrutar de respuestas fluidas y de calidad. La versión inicial soporta 8B pero las siguientes versiones están diseñadas para uso en servidores grandes.
Existen versiones modificadas por los usuarios, conocidas como «fine-tuning». No son oficiales, pero suelen servir para darle otro propósito al modelo. Por ejemplo, Unsloth, que es de código abierto, permite realizar modificaciones para reducir su consumo de memoria y energía sin perder su calidad. En este caso, encontrarías un Llama 3.2 de Unsloth, que, según afirman los desarrolladores, reduce su consumo a la mitad. Según la documentación, se han realizado cambios en sus parámetros de cuantificación y en su estructura de datos.
¿Cuáles son los requisitos?
En general, los requisitos para realizar una conversación con un modelo de lenguaje extenso varían. Si vas a trabajar con modelos de entre uno y tres mil millones de parámetros (1B a 3B), se necesitan 4 GB de RAM y alrededor de 2 GB de espacio libre en disco. Esta configuración es ideal para la mayoría de equipos que no cuentan con componentes especializados, como chips de aprendizaje neuronal o tarjetas gráficas con soporte CUDA.
A partir de ahí, cuando se llega a los modelos 7B, se necesitan 8 GB de RAM; para los modelos de 13B, 16 GB; y para los de 33B, 32 GB. Como referencia, el modelo de Meta con más parámetros, 435B, necesita entre 200 GB y 450 GB de espacio en disco y unos miniservidores de más de 200 GB de RAM.
Ten en cuenta que los requisitos no incluyen el programa, por lo que el espacio que consume en el disco es mucho mayor. Además, aquí se mencionan los requisitos de memoria RAM, que difieren de los de la memoria VRAM de las tarjetas gráficas. Las tarjetas gráficas pueden procesar la información mucho más rápido sin sacrificar los recursos de las tarjetas de memoria convencionales.
¿Cuáles son las limitaciones?
Los modelos de lenguaje extenso nunca ofrecerán información real al 100 %, ya que se basan en comprender información de libros, páginas web y otros recursos digitales. Por ejemplo, leer una noticia en línea no es lo mismo que ser testigo de ella. Además, los modelos no identifican los sentimientos humanos, sino que se entrenan en redes neuronales para que se guarden en parámetros, una especie de «neuronas». Por tanto, existe el riesgo de que en las conversaciones se inventen datos, es decir, que haya «alucinaciones». Por ejemplo, dar contexto a un refrán que jamás existió.
También se sabe que un modelo solo entrena información hasta una fecha concreta. Por lo tanto, existe el riesgo de que responda erróneamente a eventos más recientes. Ahí es donde algunos desarrolladores crean sus «fine-tuning» (ajustes precisos), versiones «retocadas» de esos modelos, ya sea reentrenándolos u optimizándolos para que respondan más rápido y sin pensarlo dos veces. Los desarrolladores deben tener cuidado, porque si se entrena demasiado y se produce un sobreajuste (al sobrepasar la capacidad de almacenamiento del modelo), este puede convertirse en un problema al ofrecer respuestas.
Una solución sería que el bot pudiera leer documentos con texto reconocible (técnicamente se recurre al Retrieval-Augmented Generation o RAG). Con ayuda del razonamiento, podría realizar los ejercicios de forma orientada. No es infalible, pero sí efectiva para reducir alucinaciones. Imagina que, aunque parezca absurdo, el bot busca el contexto de tu pregunta para darte una respuesta en rima o en forma de canción a partir de un libro de canciones en lugar de solo palabras al azar.
Consejos
Cuando se realiza una charla con un bot conversacional, debes saber que estos reciben un prompt para que te ofrezcan una respuesta clara. Podríamos decir que el prompt es un indicador de contexto. Procura que el contexto sea claro, evitando frases vagas o irreales para que el bot pueda entender lo que vas a decir. Por ejemplo:
Eres un profesor de matemáticas de secundaria. Este profesor es jovial y didáctico, y es capaz de enseñar con calma los temas de su curso a los alumnos, que comprenden entre 12 y 15 años. Además, propone ejemplos y presenta ejercicios para resolver en clase, con la intención de que los estudiantes siempre aprendan. Si las respuestas son incorrectas, este profesor intenta explicar el porqué y le muestra cómo se debería resolver. Como alumno, le pediría primero: «Enséñame sobre fracciones con ejemplos y ejercicios».Hablando de contexto, aprovecha este prompt para probar cómo responde el bot con el LLM que has elegido. Este prompt asumirá el papel de un profesor y enseñará a un grupo de estudiantes de secundaria. Si notas que el bot no responde como debería, es porque no está bien entrenado.
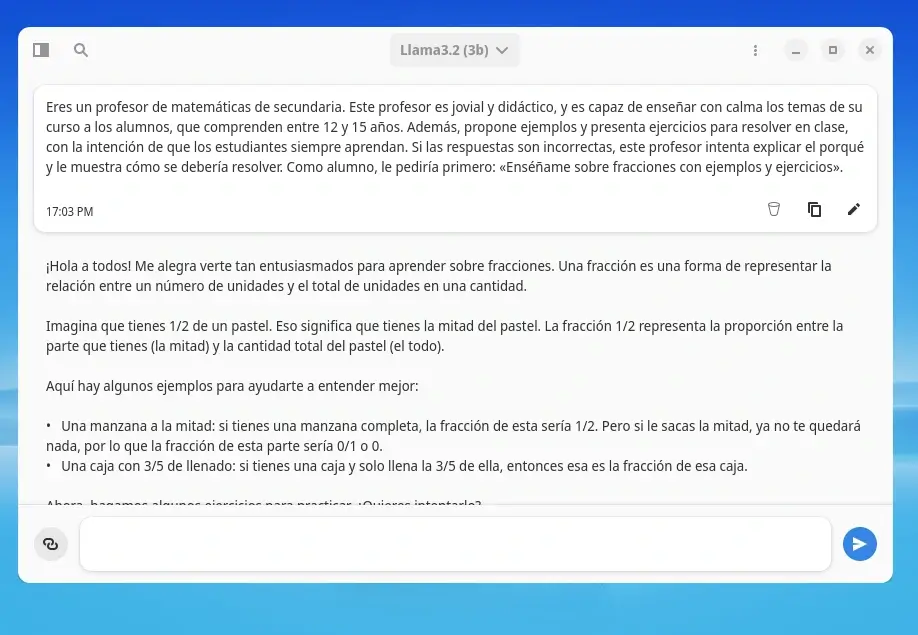
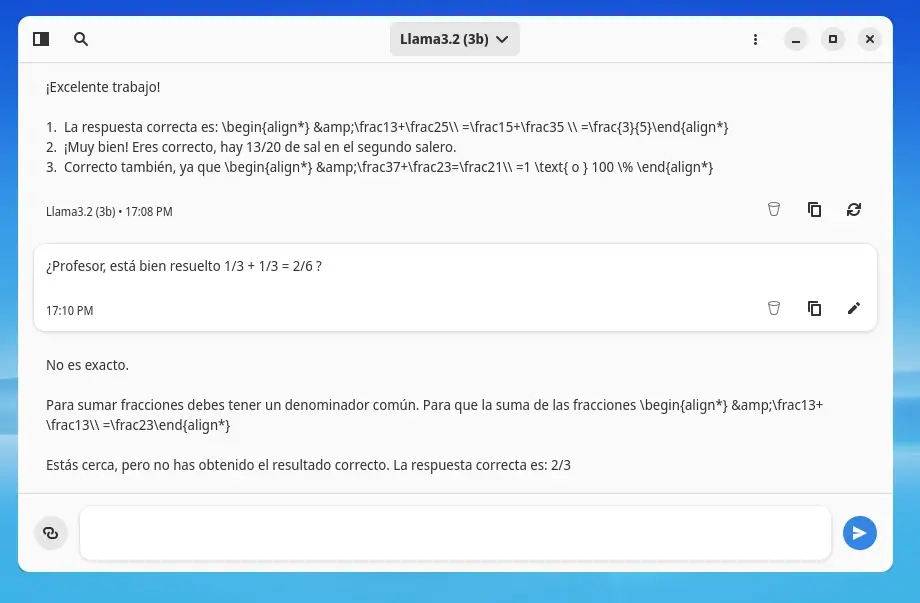
Puedes revisar varios ejemplos de prompts escritos en inglés.
Programas compatibles
Los programas a continuación ofrecen tutoriales para instalar un modelo de lenguaje extenso y empezar a conversar.
- Jan
- Alpaca (depende de Ollama)
- GPT4All
- Atomic Chat (derivado de Jan, solo vía Appimage y en pruebas)
- AnythingLLM (requiere la ejecución de un script para descargar Appimage)
- Contenedores
- Podman AI Lab (requiere Podman y una extensión, aún no disponibles en Deepin 23)
- LocalAI (comando:
podman run -p 11437:8080 --name local-ai -ti localai/localai:latest)
También se puede probar montando una instancia web propia y conversar con WebLLM desde el navegador. Es necesario que WebGPU esté activado en los ajustes del navegador. Para comprobar si WebGPU está funcionando en los navegadores Chrome, Brave o derivados, visita su página en chrome://gpu.
Algunos programas permiten montar su servidor web con el protocolo OpenAI. Puedes recurrir a la interfaz de aplicación para realizar pruebas o integrarlo con otros programas de inteligencia artificial. El puerto lo decide el programa en cuestión, aunque se puede modificar.
| Método | Ruta | Enlace de ejemplo a la URL completa (tomando al puerto GPT4All) |
|---|---|---|
GET | /v1/models | http://localhost:4891/v1/models |
GET | /v1/models/<name> | http://localhost:4891/v1/models/Phi-3%20Mini%20Instruct |
POST | /v1/completions | http://localhost:4891/v1/completions |
POST | /v1/chat/completions | http://localhost:4891/v1/chat/completions |
Puedes revisar los modelos con curl http://localhost:4891/v1/models (tomando con ejemplo al puerto de GPT4All).
Lectura adicional
- Mensajería instantánea
- Asistente virtual
- Configurando modelos IA en UOS (tutorial de Marco Gutama)