
CONFIGURANDO MODELOS IA EN DEEPIN
La inteligencia artificial es una tecnología que está ganando relevancia en los sistemas modernos y Deepin es uno de ellos, por lo que en su versión 23 ha introducido su propia interfaz que posibilita interactuar con modelos de IA.
La misma se basa en la utilización de modelos de aprendizaje automático LLM (Machine Learning) que se entrenan previamente para llevar a cabo diversas tareas como reconocimiento de imágenes, análisis de datos o creación de contenido, resumen de texto, etc.
En el presente artículo te mostramos cómo utilizar modelos de lenguaje utilizando dos métodos. Primeramente, utilizando recursos locales y, posteriormente, aprenderás cómo hacerlo utilizando recursos en la nube. Así es que lee hasta el final y estarás utilizando la IA en Deepin en unos pocos minutos.
Deepin con UOS-AI nos permite utilizar modelos de lenguaje (LLM) que sean compatibles con el API de Chat de OpenAI. Los modelos Ollama lo son .
Ollama, en conjunto con el modelo compatible con la API de OpenAI del tutorial (llama3.1), necesita un espacio en disco de alrededor de 7 GB. Se recomienda un CPU moderno con 8 cores y un mínimo de 8 GB de RAM.
PASO 1
Descargar Ollama, abrir la terminal y ejecutar el siguiente comando:
curl -fsSL https://ollama.com/install.sh | sh
PASO 2
Detener servicio
El servicio por defecto se ejecuta como root, lo cual provoca que cualquier modelo que descarguemos se guarde en: /usr/share/ollama/. Dado que los modelos ocupan bastante espacio, no es conveniente que los modelos se guarden allí. Entonces ejecutamos el siguiente comando:
sudo systemctl stop ollamaOpcional para desactivar el inicio automático del servicio; ejecutamos lo siguiente:
sudo systemctl disable ollamaPASO 3
Entonces, para lograr ejecutar el servicio sin root, ejecutamos el siguiente comando:
ollama serve
PASO 4
Ahora deberás descargar un modelo. Para este ejemplo se va a utilizar Llama 3.1; sin embargo, puedes revisar todos los modelos disponibles en https://ollama.com/library. Entonces ejecuta el siguiente comando en otra terminal para descargar el modelo:
ollama run llama3.1Una vez que se descargue el modelo, ya podremos interactuar con el mismo desde la terminal.
PASO 5
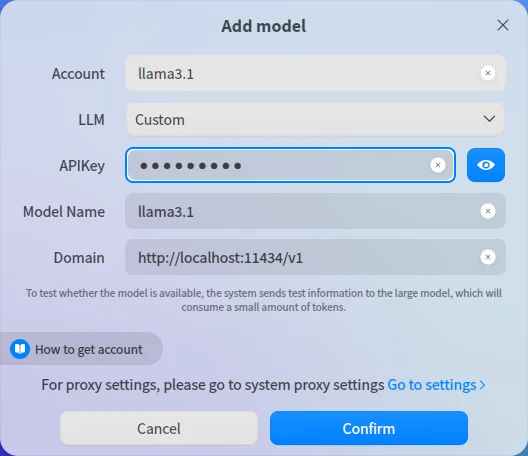
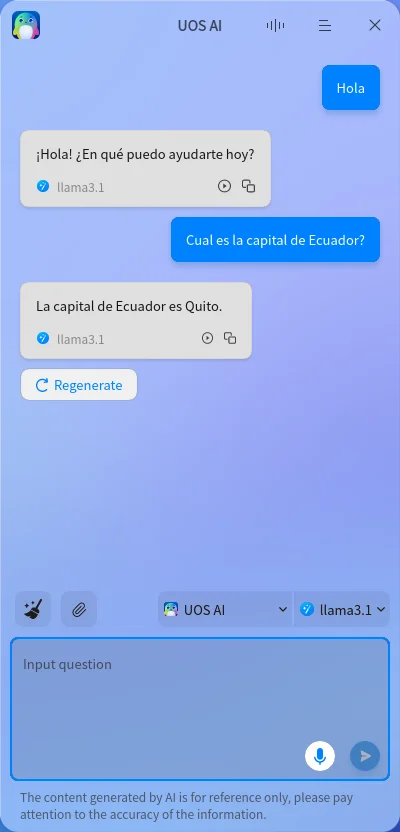
Abrimos UOS-AI, agregamos el modelo como en la imagen.
Account: Cualquier nombre
LLM: Custom
APIKey: cualquier valor, no dejar vacio.
Model Name: llama3.1
Domain: http://localhost:11434/v1
Después de exitosamente haber finalizado los pasos mencionados arriba, tendrás UOS-AI funcionando con Llama3.1, tal y como en la imagen a continuación.
P U B L I C I D A D
Nuestros anuncios no son intrusivos y nos ayudan a permanecer en línea. Por favor apóyanos por medio de no bloquear los anuncios
PASO 1
En el navegador, nos dirigimos a https://openrouter.ai/ y creamos una cuenta.
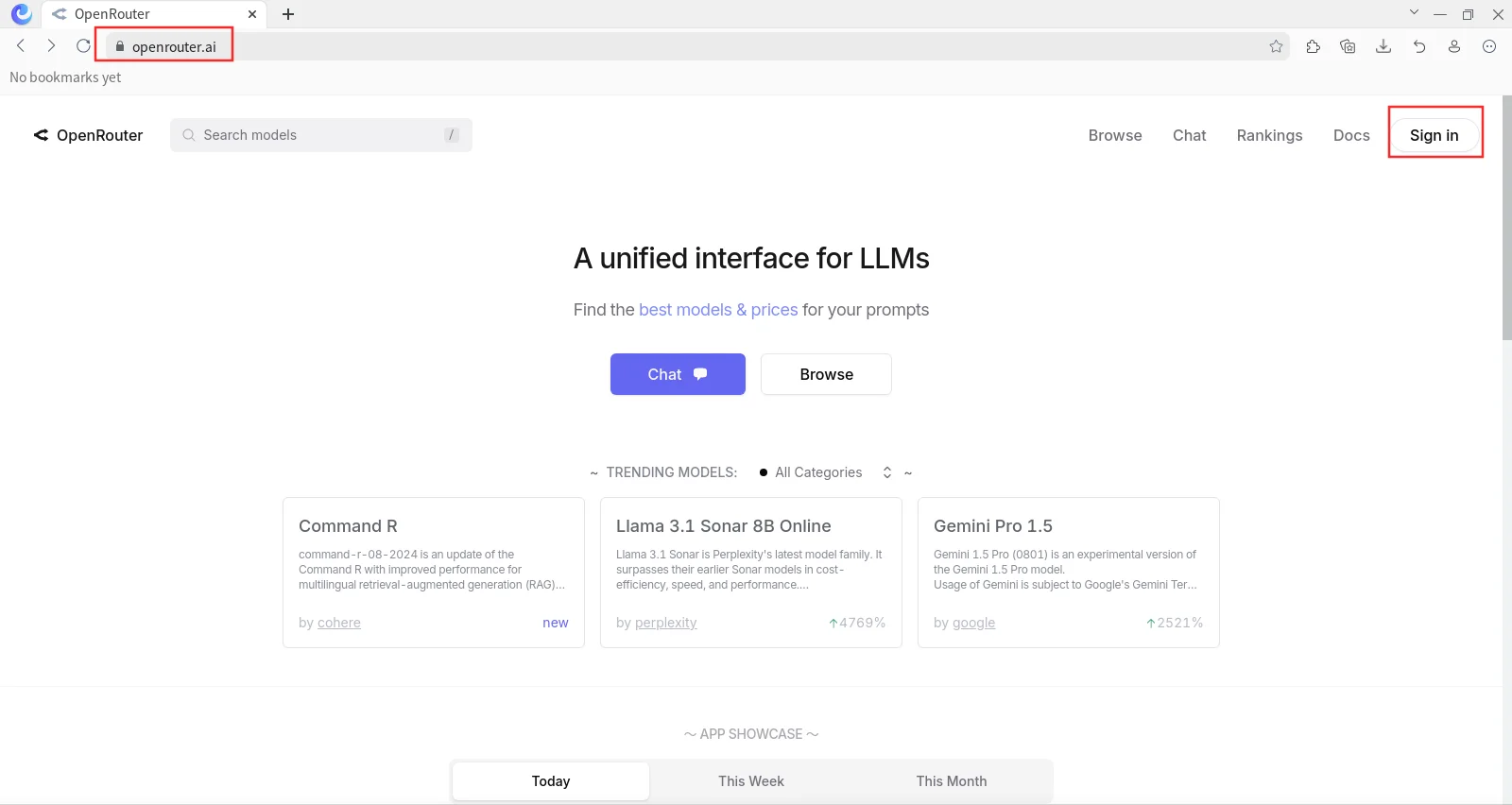
PASO 2
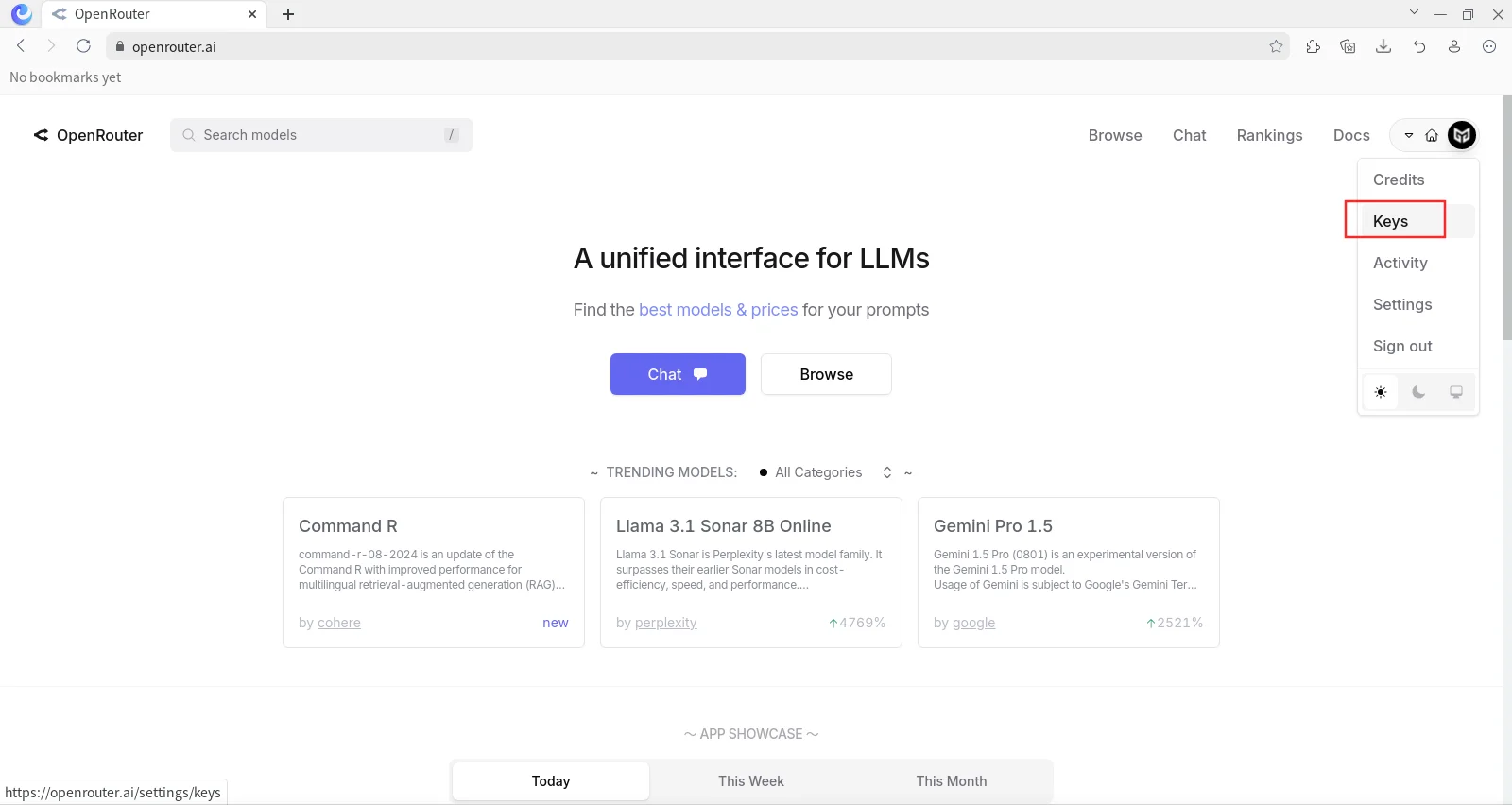
Creamos una key en https://openrouter.ai/settings/keys
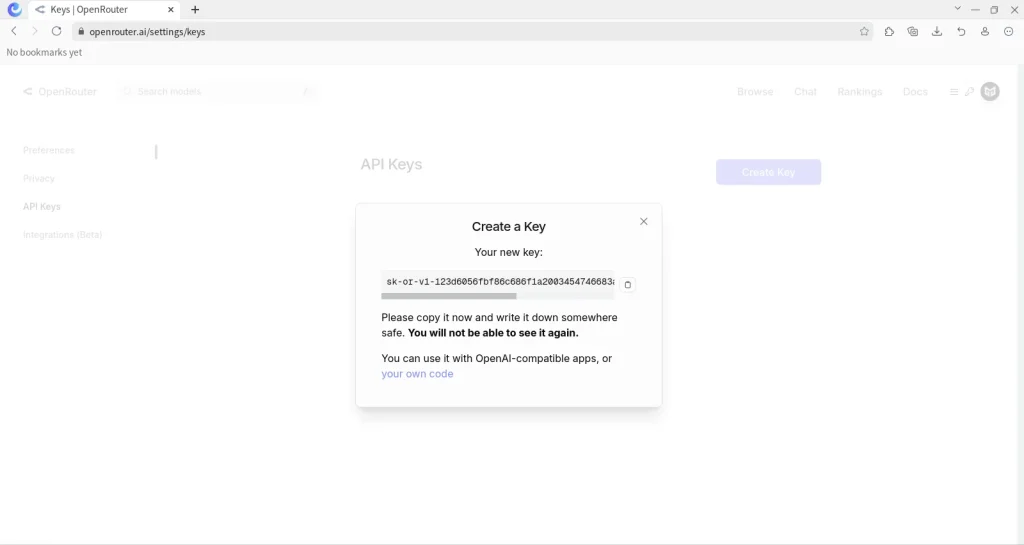
La key generada debemos guardarla en algun archivo, ya que openrouter no nos permitira verla nuevamente.
PASO 3
Para buscar modelos gratuitos dirigirnos a https://openrouter.ai/models?max_price=0
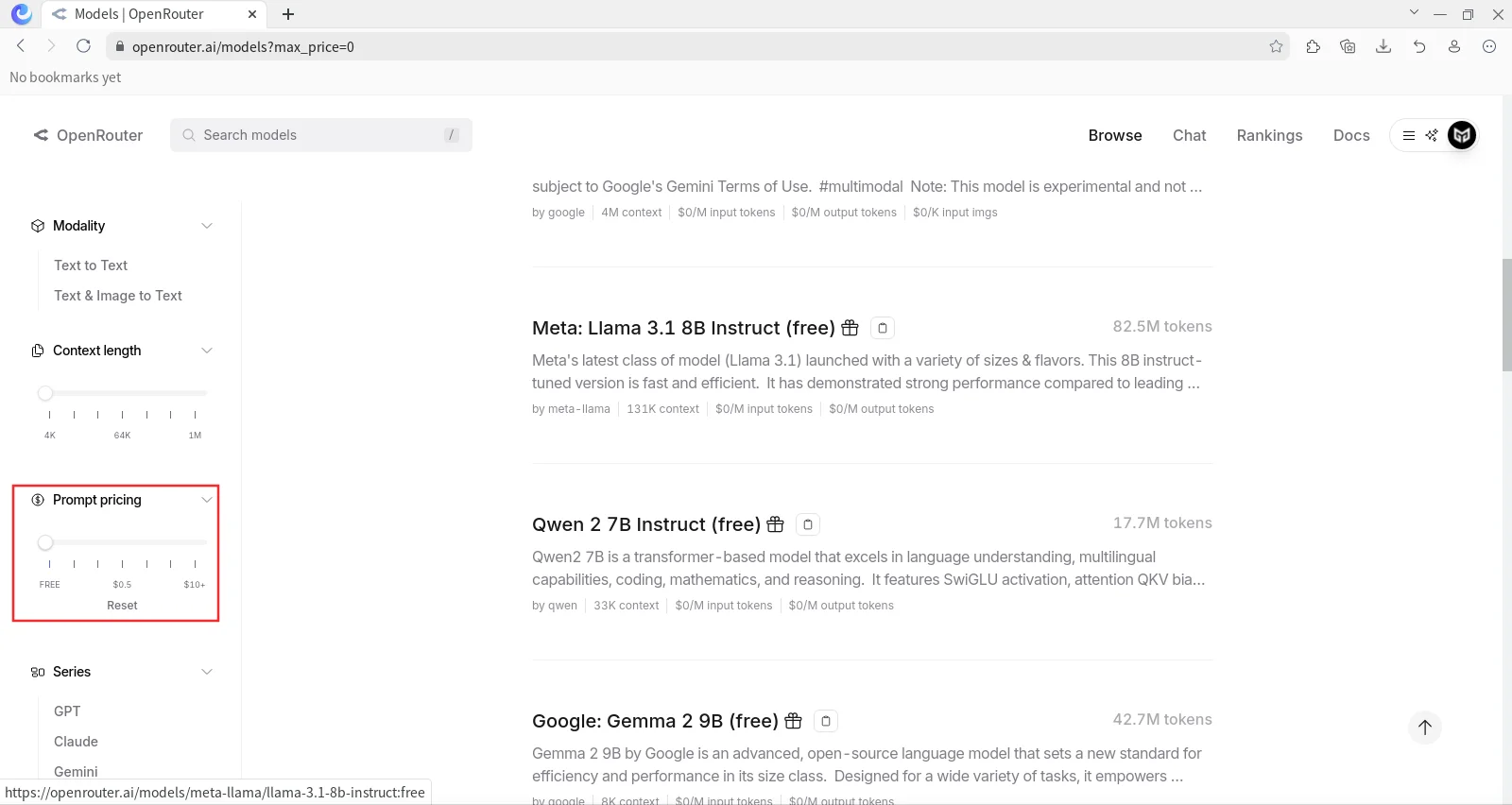
PASO 4
Una vez seleccionado un modelo específico, entonces identificamos el nombre del mismo. Para el ejemplo mostrado a continuación, el nombre del modelo es: meta-llama/llama-3.1-8b-instruct:free
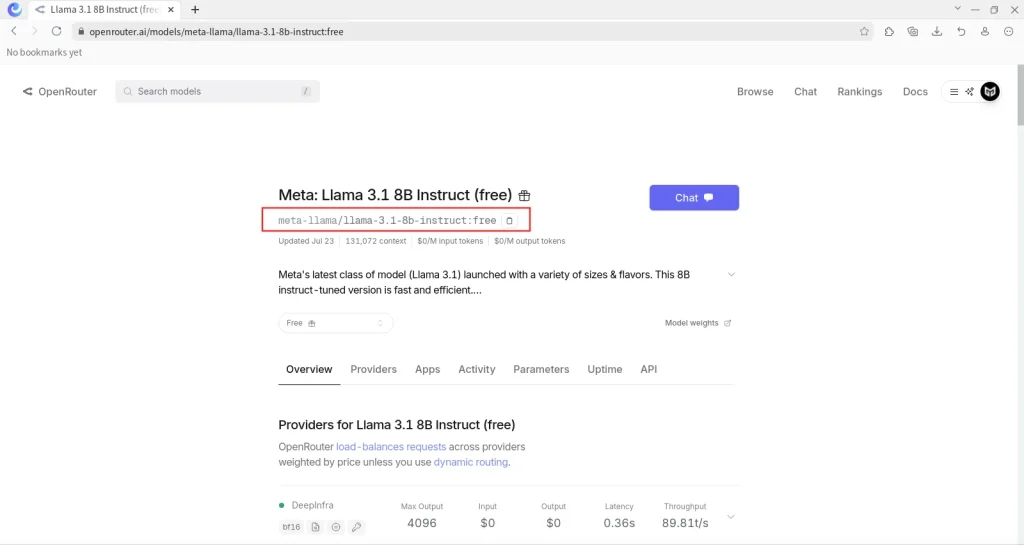
PASO 5
Abrimos UOS-AI, agregamos el modelo como en la imagen
Account: cualquier nombre
LLM: Custom
APIKey: key generado en openrouter
Model Name: nombre del modelo
Domain: https://openrouter.ai/api/v1
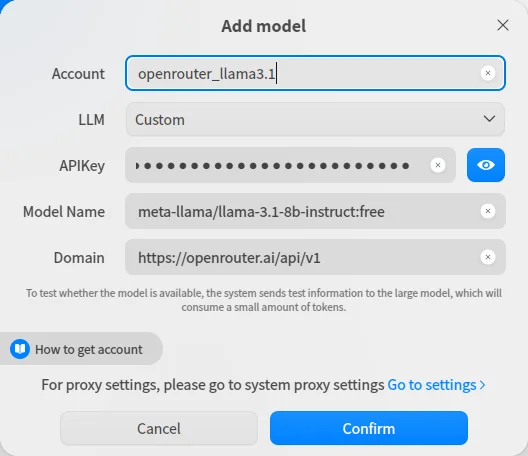
Eso es todo; si seguiste los pasos exitosamente, entonces deberás poder usarlo como el siguiente ejemplo de uso: Hago una consulta y pido que utilice como fuente un archivo adjunto.

conclusión
Al mantener los datos sensibles localmente, se reduce la necesidad de enviarlos a través de redes públicas, minimizando el riesgo de brechas, renunciando a datos sensibles y/o IP a modelos de entrenamiento públicos y, en caso de estar gestionando la IA localmente para un ambiente empresarial, también estaremos ayudando a cumplir con las regulaciones de protección de datos.
Otros, sin embargo, preferirán la nube debido a no tener que utilizar recursos locales, los cuales podrían ser utilizados para otras aplicaciones y al mismo tiempo, logrando mayor desempeño en ordenadores no tan poderosos.
Referencias
Ollama: https://github.com/ollama/ollama
Requisitos para modelo Llama3.1: https://llamaimodel.com/requirements/



Excelente tutorial muchas gracias por compartirlo.
Genial publicación Marco Gutama espero poder leer más de usted.
Marco Gutama espero poder leer más de usted.
Siempre me estuve preguntando cómo hacer funcionar eso. Gracias.
Muy detallado y funciona, gracias.
Muy útil, muchísimas gracias, va de maravillas.
O hay algo que estoy haciendo muy mal, o no se que pasará…
Error en el primer comando! jajajaja «bash: -fsSL: orden no encontrada»
A mí se me instaló sin problema alguno. ¿Puede mostrar una toma de pantalla o copiar y pegar exactamente qué comandos está ingresando y cuál es el error exacto que le sale? ¿Tiene «curl» instalado en su sistema? Si no lo tiene, asegúrese de instalarlo antes de comenzar el tutorial.
También, no escriba el signo $ al principio de la línea de comandos como aparece en el tutorial; eso es solo cosmético.
Saludos.
Ese era mi problema, ahora todo funcionando sin problemas, gracias.
Saludos.