Ollama es el software que facilita la ejecución de modelos de lenguaje extenso. Este software es compatible con UOS AI, la inteligencia artificial del sistema operativo Deepin.
Cómo instalar
Existen varias formas de instalar Ollama: mediante un ejecutable, a través de Python (vía pip) o mediante Snap (desaconsejado en Deepin 23). En Deepin, al trabajar con contenedores, deberás preparar uno de ellos e instalar allí.
Instalar desde Distrobox
Desde el sitio web, podemos hacer que Distrobox prepare nuestro contenedor por nosotros. Solo hay que ejecutar este comando para iniciar la instalación:
distrobox create -i docker.io/ollama/ollama:latest -n ollama -pComo Distrobox permite instalar contenedores desde Docker, la instalación se realiza automáticamente. Este creará un acceso directo (de la misma forma con Brave, por ejemplo).
Al finaliza la descarga, ejecutamos el siguiente comando:
distrobox enter ollamaAutomáticamente, se realizará las primeras configuraciones del programa, los cuales podremos editar desde el comando ollama.
Recomendaciones
Se necesitan al menos 4 GB de memoria RAM disponible (para Gemma 4, con 4 mil millones de parámetros), 10 GB de espacio libre en el disco duro y un procesador de ocho núcleos de cuarta generación (desde 2014 hasta la actualidad). Opcionalmente, se puede trabajar con una GPU, que ofrecerá respuestas más inmediatas a Ollama. Estas especificaciones son básicas, pero resultarán útiles para la mayoría de las tareas de solo texto.
Recuerda que algunos desarrolladores ofrecen versiones con ajuste preciso, como Unsloth, que pretende agilizar las respuestas sin sacrificar más recursos y que las sube a los repositorios. Dejamos ese asunto a tu criterio.
Otros casos
Para el caso de Snap, que Deepin ya no permite trabajar con esta tecnología, se instala como: sudo snap install ollama
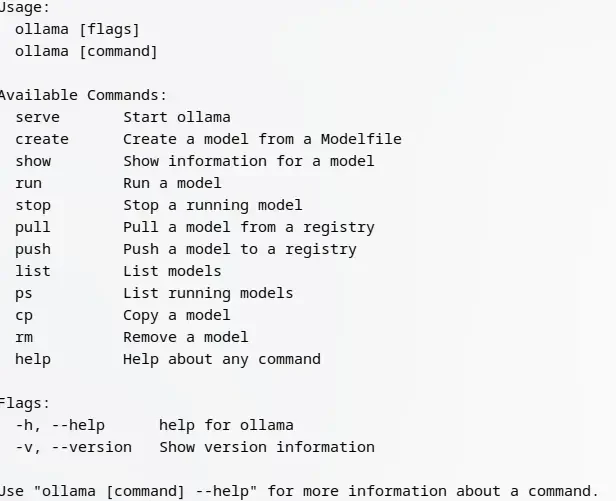
Cómo ejecutar Ollama
- Ejecuta
ollama(o tambiénollama serve)- Si has instalado por Distrobox, basta con acceder al contenedor correspondiente y ejecutar
ollama serveen una pestaña aparte.
- Si has instalado por Distrobox, basta con acceder al contenedor correspondiente y ejecutar
- Prueba a ejecutar un comando, por ejemplo:
ollama run ssfdre38/gemma4-turbo:e2b- El comando de referencia es Gemma 4 Turbo. Recomendado para la mayoría de usuarios.
- Consulta la web para instalar los modelos disponibles en su repositorio.
- El servidor es
127.0.0.1:11434, para trabajar, necesitarás un cliente de bot conversacional compatible con el protocolo OpenAI
También puedes:
- Revisar un modelo
- Acceder a la carpeta
~/.ollama/models - Detener un modelo por comando, por ejemplo:
ollama stop ssfdre38/gemma4-turbo:e2b(recomendable para múltiples modelos y evitar sobregastos de RAM) - Eliminar un modelo por comando, por ejemplo:
ollama rm ssfdre38/gemma4-turbo:e2b
Ollama ofrece su dirección web, a la que no se puede acceder inmediatamente, sino a través de un programa compatible. Por fortuna, puedes probar fácilmente su funcionamiento con la aplicación Follamac. El programa no instala directamente el navegador, pero te permite iniciar una conversación y revisar su rendimiento. También puedes usar Brave (para integrar el navegador) o conectar con dispositivos Android (debes localizar la dirección IP del dispositivo primero). Si tienes Deepin 23, puedes usar su asistente personal, que integra perfectamente las funciones del sistema operativo sin sacrificar tu privacidad.
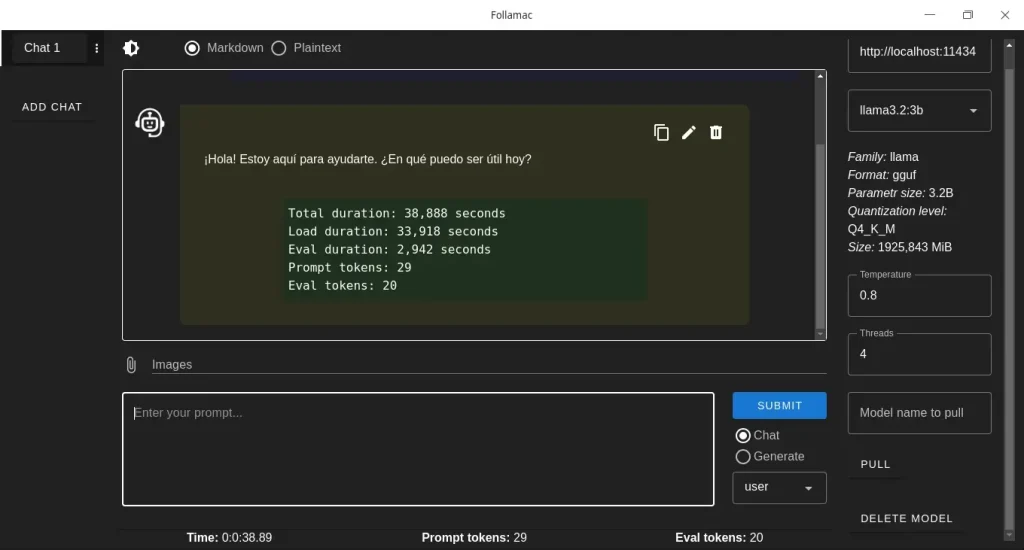
Además del servidor y modelo, la API key de la instancia (clave API) es ollama. Esto es opcional, pero algunos programas exigen que se introduzca.
Fuente: Blog de Ollama
Otros consejos
Integrar con UOS AI (desde Deepin 23)
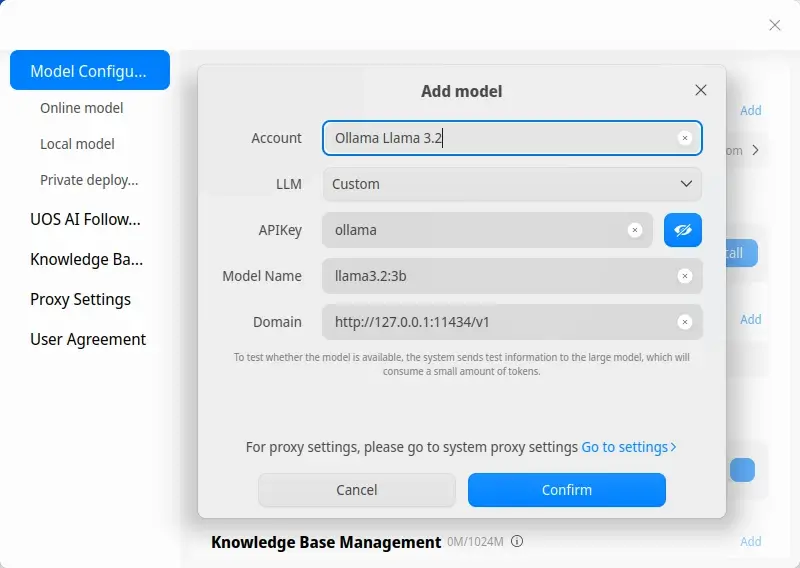
Para integrar UOS AI en Deepin, solo tienes que introducir la API del servidor, no necesitarás más pasos. Por suerte, el programa te permite añadirla en unos clics y de forma gráfica. Estos son los datos:
- Nombre: Ollama
- LLM: Personalizada
- APIKey:
ollama - Nombre de modelo:
ssfdre38/gemma4-turbo:e2b(recomendado)llama3.2:3b(tomado de Llama3 para las ilustraciones)
- Dirección API:
http//:localhost:11434/v1
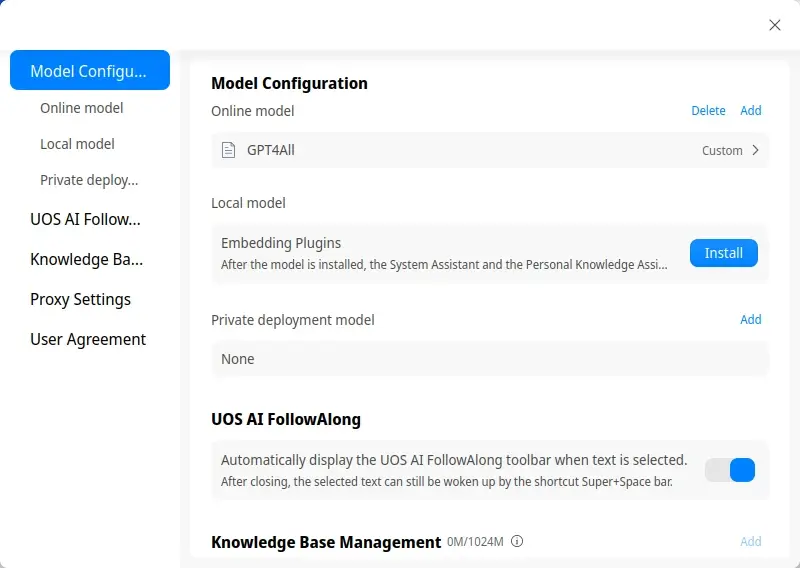
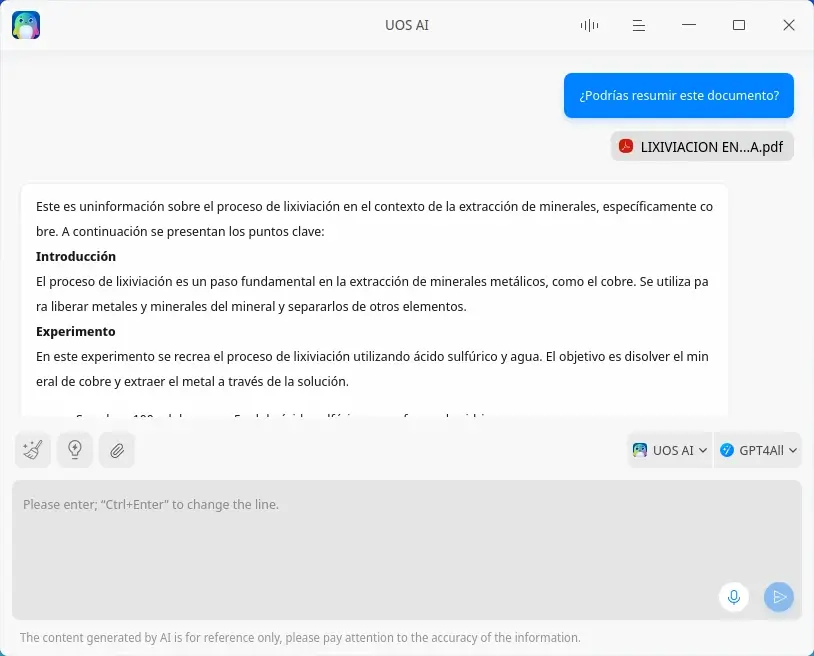
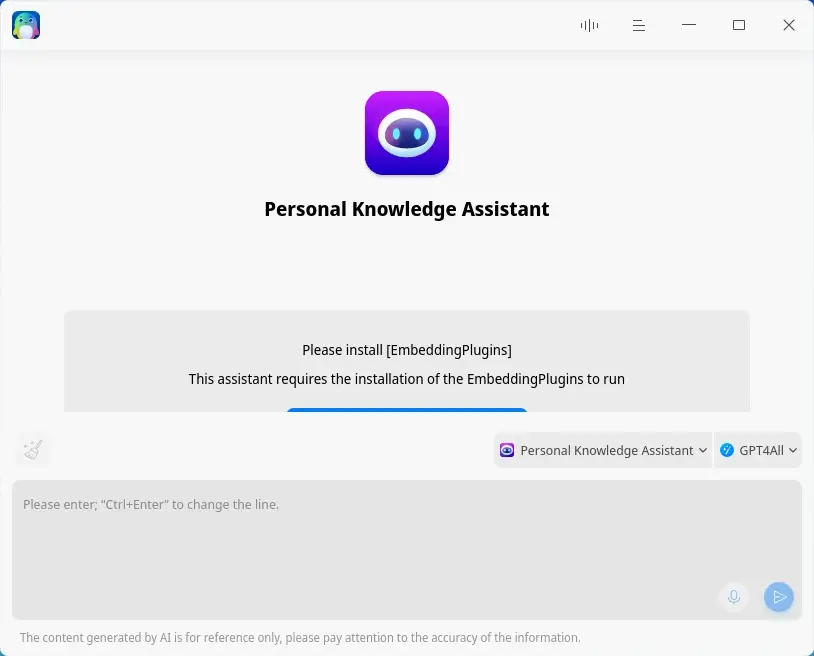
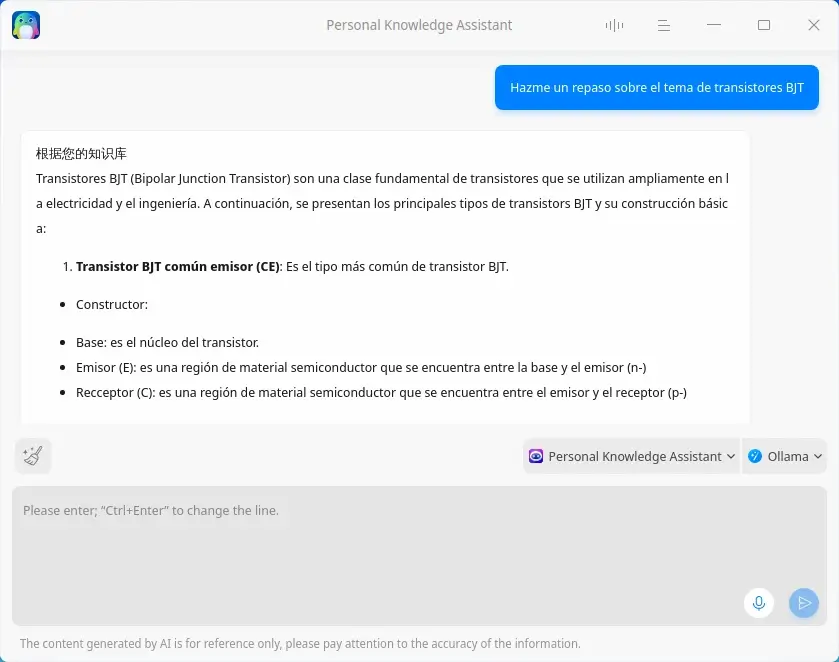
También puedes usar otras funciones, como el Personal Knowledge Assistant (asistente de conocimiento personal), en el que puedes añadir archivos para que te responda a las preguntas. Este proceso requiere de más memoria disponible y de una GPU Nvidia (con controlador CUDA) o AMD.
Primero, debes instalar los complementos de incrustación desde Deepin Store (el proceso ocupa unos KB) y, a continuación, añadir al menos un archivo desde los ajustes. El proceso llevará unos minutos, dependiendo del texto que contenga el archivo (1 hora para un documento de 300 mil palabras con una CPU Haswell ocho núcleos de 3.6 Ghz, de Intel). Dispones de casi 1 GB para incorporar archivos a su base de datos.
Recuerda que, para Deepin 23, no todas las características funcionan en español, como el dictado de texto y el menú contextual de las aplicaciones predeterminadas en Deepin. Esto se resolverá en próximas entregas.
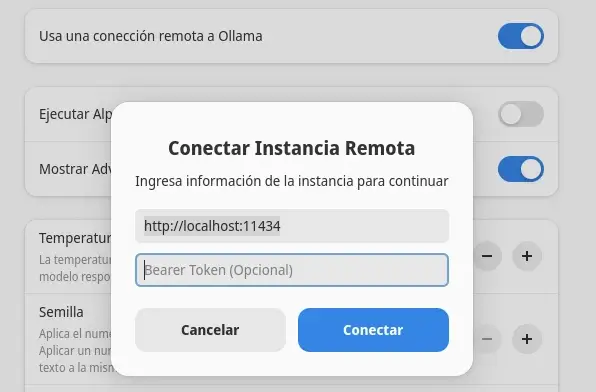
Integrar con Alpaca y GPT4All
Al igual que UOS AI, Alpaca y GPT4All son dos programas que puedes probar para aprovechar el potencial de los bots conversacionales. En este caso, solo es necesario llamar a la instancia, sin necesidad de volver a descargar los modelos. En el caso del primero, solo necesitas escribir la URL http://localhost:11434, y en el segundo, http://localhost:11434/v1 (junto con el modelo y la clave que se ofrecen en este artículo).
Cambiar puerto Ollama
Ollama establece su puerto en 11434 y puedes cambiarlo. Intenta modificar el parámetro OLLAMA_HOST manualmente. Si usas Distrobox, tendrás que configurar el puerto del contenedor primero, puesto que no es posible acceder a los archivos de configuración.
Fuente: Apuntes de Ollama